Understanding recovery time and recovery point objectives are crucial to your high availability and disaster recovery (HADR) plan as they're the foundation for any availability solution.
## Terms
**Recovery Time Objective (RTO):**
- **Definition:** Maximum time to bring resources online after an outage.
- **Impact:** Exceeding RTO can lead to financial penalties and operational disruptions.
- **Component-Level RTO:** Defined for individual components and overall solution.
**Recovery Point Objective (RPO):**
- **Definition:** Maximum acceptable data loss measured in time, as defined by business requirements
- **Example:** If RPO is 15 minutes, data can be restored to within 15 minutes of the outage.
**Defining RTO and RPO:**
- **Business Requirements:** Driven by business needs and technological capabilities.
- **Cost of Downtime:** Helps in defining realistic RTO and RPO.
- **Component Dependencies:** Overall RTO is determined by the slowest component to recover.
**High Availability (HA) vs. Disaster Recovery (DR):**
- **HA:** Localized events with minimal downtime, often measured in minutes.
- **DR:** Larger scale events requiring more time, often measured in hours or longer.
- **Separate RTOs and RPOs:** Defined for both HA and DR scenarios.
## HADR for IaaS Deployments
**SQL Server HADR Features**:
- **[[Failover Cluster Instances]] (FCI)**: Provides instance-level protection with a unique name and IP address, requiring shared storage and Active Directory Domain Services.
- **[[Always On Availability Group]] (AG)**: Offers database-level protection with primary and secondary replicas, supporting synchronous or asynchronous data movement.
- **[[Log Shipping]]**: A simple method for disaster recovery based on backup, copy, and restore, providing database-level protection.
## HADR for PaaS Deployments
- **[[Azure SQL Database]]**: Features active geo-replication and autofailover groups.
- **Azure Database for MySQL**: Guarantees 99.99% availability with built-in failover mechanisms.
- **Azure Database for PostgreSQL**: Offers a scale-out hyperscale solution called Citus, with standby replicas for high availability.
## Examples
### IaaS High Availability Solutions
1. **[[Always On Availability Group]] (AG) in a Single Region**:
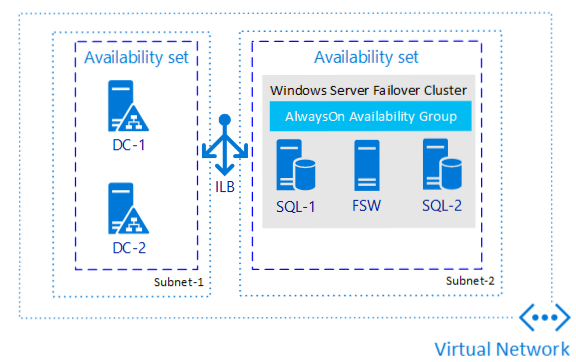
- **Description**: Protects data by maintaining multiple copies on different virtual machines (VMs).
- **Benefits**: Meets recovery time objective (RTO) and recovery point objective (RPO) with minimal-to-no data loss, provides easy access to primary and secondary replicas, and enhances availability during patching scenarios.
2. **Always On [[Failover Cluster Instances]] (FCI) in a Single Region**:
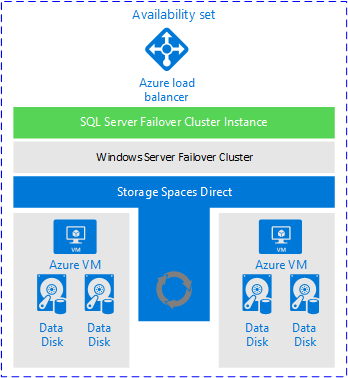
- **Description**: Traditional method for SQL Server high availability, designed for physical deployments but still applicable in virtualized environments.
- **Benefits**: Popular solution, improved shared storage with Azure Shared Disk, meets most RTO and RPO for high availability, and enhances availability during patching scenarios.
### Disaster Recovery Solutions
1. **Multi-Region or Hybrid Always On Availability Group**:

- **Description**: Configures AG across multiple Azure regions or as a hybrid architecture, with all nodes participating in the same Windows Server Failover Cluster (WSFC).
- **Benefits**: Proven solution, works with both Standard and Enterprise editions of SQL Server, provides redundancy with additional data copies, and offers both high availability and disaster recovery.
2. **Distributed Availability Group**:
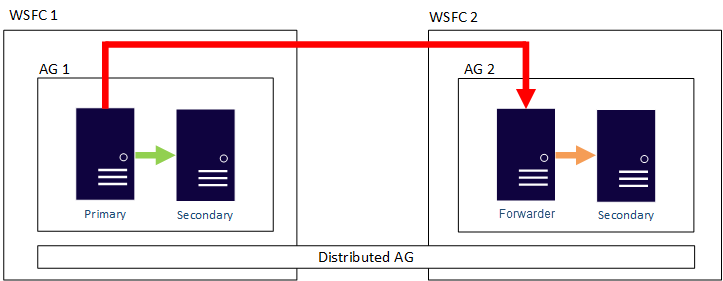
- **Description**: Enterprise Edition feature introduced in SQL Server 2016, consisting of multiple AGs with a global primary and a forwarder.
- **Benefits**: Separates WSFC as a single point of failure, easier quorum management, and supports failover between locations.
3. **Log Shipping**:
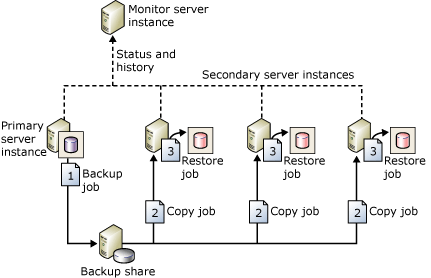
- **Description**: One of the oldest HADR methods, based on transaction log backups.
- **Benefits**: Tried-and-true feature, easy to deploy and administer, tolerant of less robust networks, meets most RTO and RPO goals for disaster recovery, and protects FCIs.
4. **Azure Site Recovery**:
- **Description**: Non-SQL Server-based disaster recovery solution provided as part of the Azure platform.
- **Benefits**: Works with more than just SQL Server, may meet RTO and possibly RPO, and integrates with the Azure platform.
### PaaS Deployment Options
1. **Azure SQL Database**:
- **Features**: Active geo-replication and autofailover groups.
- **Benefits**: High availability and disaster recovery capabilities built into the service.
2. **Azure Database for MySQL**:
- **Features**: Guarantees 99.99% availability with built-in failover mechanisms.
- **Benefits**: Reliable high availability solution for MySQL databases.
3. **Azure Database for PostgreSQL**:
- **Features**: Scale-out hyperscale solution called Citus, with standby replicas for high availability.
- **Benefits**: Scalable and highly available PostgreSQL deployment.
### Best Practices
- **Coding Retry Logic**: Emphasizes the importance of implementing retry logic in applications to handle transient failures and dropped connections.
## Resources
- [Describe recovery time objective and recovery point objective - Training | Microsoft Learn](https://learn.microsoft.com/en-us/training/modules/describe-high-availability-disaster-recovery-strategies/2-describe-recovery-time-objective-recovery-point-objective)
- [Explore high availability and disaster recovery options - Training | Microsoft Learn](https://learn.microsoft.com/en-us/training/modules/describe-high-availability-disaster-recovery-strategies/3-explore-high-availability-disaster-recovery-options)
- [Describe high availability and disaster recovery options for PaaS deployments - Training | Microsoft Learn](https://learn.microsoft.com/en-us/training/modules/describe-high-availability-disaster-recovery-strategies/5-describe-high-availability-disaster-recovery-options)